Spark Structured Streaming
Run below scripts to connect to the local standalone Spark Cluster with 4 Cores and 4G memory
The Confluent Cloud cluster bootstrap URL and API key and secret will be retrieved from Azure with service principal
from pyspark.sql import SparkSession
spark = SparkSession\
.builder\
.appName("pyspark-streaming-PG-monday.com")\
.master("spark://192.168.1.34:7077")\
.config("spark.driver.memory","4g")\
.config("spark.driver.cores","4")\
.config("spark.cores.max","4")\
.config("spark.sql.adaptive.enabled",False)\
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
from pyspark.sql.types import *
import pyspark.sql.functions as F
from azure.keyvault.secrets import SecretClient
from azure.identity import ClientSecretCredential
import warnings
warnings.filterwarnings("ignore")
# connect to Azure Key Vault and authenticate by service principal
keyVaultName = "xxx-postgres"
KVUri = f"https://{keyVaultName}.vault.azure.net"
client_id='xxxxxxxx-xxxx-498e-87f1-xxxxxxxxxxxx'
client_secret='Ygp12~xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
tenant_id='xxxxxxxx-xxxx-xxxx-8fef-xxxxxxxxxxxx'
credential = ClientSecretCredential(client_id=client_id, client_secret=client_secret,tenant_id=tenant_id,connection_verify=False)
client = SecretClient(vault_url=KVUri, credential=credential, connection_verify=False)
# retrieve Confluent bootstrap API key and secret from Azure Key Vault
secretName = "confluent-bootstrap"
retrieved_secret = client.get_secret(secretName)
confluent_bootstrap = retrieved_secret.value
secretName = "confluent-key"
retrieved_secret = client.get_secret(secretName)
confluentApiKey = retrieved_secret.value
secretName = "confluent-secret"
retrieved_secret = client.get_secret(secretName)
confluentSecret = retrieved_secret.value
Run below scripts to consume customer login kafka topic
df_contact = (spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "%s.southeastasia.azure.confluent.cloud:9092" %(confluent_bootstrap))
.option("subscribe", "eks_shuup_last_login_test_03")
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username='{}' password='{}';".format(confluentApiKey, confluentSecret))
.option("kafka.ssl.endpoint.identification.algorithm", "https")
.option("kafka.sasl.mechanism", "PLAIN")
.option("startingOffsets", "latest")
.option("maxOffsetsPerTrigger",10)
.load())
contactStringDF = df_contact.selectExpr("CAST(value AS STRING)")contact_schema = StructType([
StructField("shuup_id", IntegerType(), True),
StructField("username", StringType(), True),
StructField("customer_name", StringType(), True),
StructField("email", StringType(), True),
StructField("phone", StringType(), True),
StructField("marketing_permission", BooleanType(), True),
StructField("monday_item_id", StringType(), True),
StructField("modified_on", StringType(), True),
StructField("last_login", StringType(), True),
])
### convert the json format to the schema defined above ###
contactDF = contactStringDF.select(from_json(col("value"), contact_schema).alias("value")).select("value.*")
contactDF = contactDF.fillna("")
### convert unix timestamp to pg timestamp with timezone
contactDF = contactDF.withColumn("modified_on", F.to_timestamp(col("modified_on")/1000))
contactDF = contactDF.withColumn("modified_on", to_timestamp("modified_on" , "yyyy-MM-dd HH:mm:ss.SSS Z"))
contactDF = contactDF.withColumn("last_login", F.to_timestamp(col("last_login")/1000))
contactDF = contactDF.withColumn("last_login", to_timestamp("last_login" , "yyyy-MM-dd HH:mm:ss.SSS Z"))
contactDF.createOrReplaceTempView("contact_update")
### decrypt the sensitive data ###
contactDF = spark.sql("select a.shuup_id, cast(aes_decrypt(unbase64(a.username),'%s','CBC') AS STRING) as username \
, cast(aes_decrypt(unbase64(customer_name),'%s','CBC') AS STRING) as customer_name \
, cast(aes_decrypt(unbase64(email),'%s','CBC') AS STRING) as email \
, cast(aes_decrypt(unbase64(phone),'%s','CBC') AS STRING) as phone \
, marketing_permission, monday_item_id as monday_contact_id, a.last_login, a.modified_on from contact_update a" %(encrypt_key, encrypt_key, encrypt_key, encrypt_key))
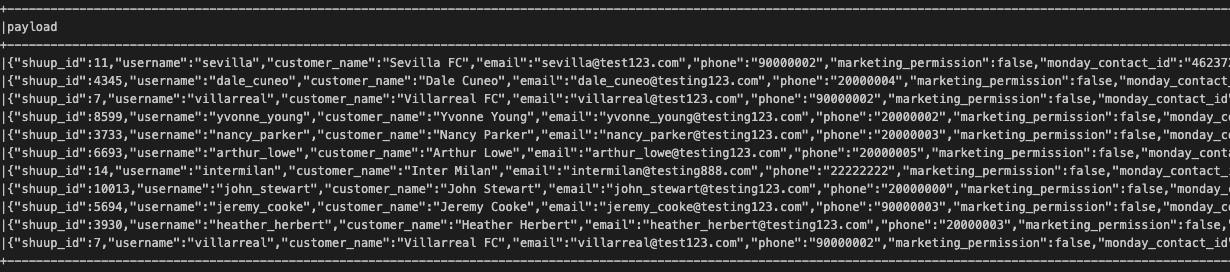
### consolidated all required into 1 payload field in order to cal rest api to update to Monday.com
contactDF = contactDF.withColumn("payload", to_json(struct(col("*"))))
To verify the decrypted data from Kafka, output the data stream into memory as shown below
contactQuery = contactDF \
.writeStream \
.queryName("contact")\
.format("memory")\
.start()
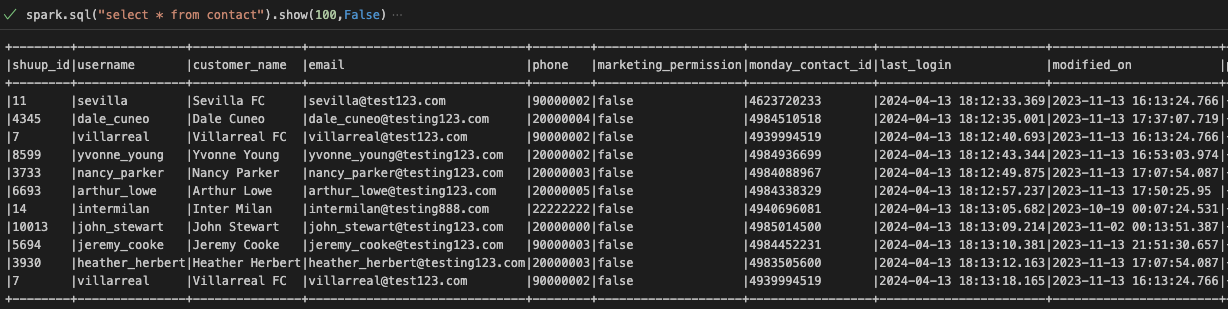
spark.sql("select * from contact").show(100,False)
Sensitive data such as customer names and email addresses are decrypted, revealing the original values.
The payload data is utilized for a REST API call to send data to Monday.com via a Spark UDF.
The above code simply streams data to the console for monitoring or debugging purposes. In this section, I will demonstrate how to save the streaming dataframe to PostgreSQL tables.
Below are two functions in db_connect.py to configure the database connection and build the upsert query.
""
psycopg2_database_helper.py - Helper code to Upsert Spark DataFrame to Postgres using psycopg2.
"""
from typing import List, Iterable, Dict, Tuple
from contextlib import contextmanager
from psycopg2 import connect, DatabaseError, Error
from psycopg2.extras import execute_values
#from pyspark.sql import DataFrame, Row
def get_postgres_connection(host: str,
database: str,
user: str,
password: str,
port: str):
"""
Connect to postgres database and get the connection.
:param host: host name of database instance.
:param database: name of the database to connect to.
:param user: user name.
:param password: password for the user name.
:param port: port to connect.
:return: Database connection.
"""
try:
conn = connect(
host=host, database=database,
user=user, password=password,
port=port
)
except (Exception, DatabaseError) as ex:
print("Unable to connect to database !!")
raise ex
return conn
def build_upsert_query(cols: List[str],
table_name: str,
unique_key: List[str],
cols_not_for_update: List[str] = None) -> str:
"""
Builds postgres upsert query using input arguments.
Note: In the absence of unique_key, this will be just an insert query.
Example : build_upsert_query(
['col1', 'col2', 'col3', 'col4'],
"my_table",
['col1'],
['col2']
) ->
INSERT INTO my_table (col1, col2, col3, col4) VALUES %s
ON CONFLICT (col1) DO UPDATE SET (col3, col4) = (EXCLUDED.col3, EXCLUDED.col4) ;
:param cols: the postgres table columns required in the
insert part of the query.
:param table_name: the postgres table name.
:param unique_key: unique_key of the postgres table for checking
unique constraint violations.
:param cols_not_for_update: columns in cols which are not required in
the update part of upsert query.
:return: Upsert query as per input arguments.
"""
cols_str = ', '.join(cols)
insert_query = """ INSERT INTO %s (%s) VALUES %%s """ % (
table_name, cols_str
)
if cols_not_for_update is not None:
cols_not_for_update.extend(unique_key)
else:
cols_not_for_update = [col for col in unique_key]
unique_key_str = ', '.join(unique_key)
update_cols = [col for col in cols if col not in cols_not_for_update]
update_cols_str = ', '.join(update_cols)
update_cols_with_excluded_markers = [f'EXCLUDED.{col}' for col in update_cols]
update_cols_with_excluded_markers_str = ', '.join(
update_cols_with_excluded_markers
)
if len(update_cols) > 1:
equality_clause = "(%s) = (%s)"
else:
equality_clause = "%s = %s"
on_conflict_clause = f""" ON CONFLICT (%s) DO UPDATE SET {equality_clause} ;"""
on_conflict_clause = on_conflict_clause % (
unique_key_str,
update_cols_str,
update_cols_with_excluded_markers_str
)
return insert_query + on_conflict_clause
I have created a class that can be invoked by a Spark streaming DataFrame using foreach to save data to the database table.
# get db credentials from aws secret manager
from aws_secretmanager import *
pg_password=get_secret('aks-id')
pl_mac=get_secret('pl-mac')
from db_connect import *
from ast import literal_eval
import json
from pyspark.sql.functions import *
# define a class to update postgres db table
class callPGupdateClass:
def __init__(self):
# Initialize resources or perform any necessary setup
pass
def open(self, partition_id, epoch_id):
# Open connection or perform any necessary setup
# Return `True` if successful, `False` otherwise
print('................................................')
table_unique_key = ['shuup_id']
table_name = 'shuup_common_contact'
no_update_col = ['payload']
#col=contactDF.schema.names
col = ['shuup_id',
'user_name',
'customer_name',
'email',
'phone',
'marketing_permission',
'monday_contact_id',
'last_login',
'modified_on']
upsert_query = build_upsert_query(
cols=col,
table_name=table_name, unique_key=table_unique_key,
cols_not_for_update = no_update_col
)
database_credentials = {
'host': pl_mac,
'database': 'common',
'user': 'aks_id',
'password': pg_password,
'port': '5532'
}
self.upsert_query = upsert_query
self.conn = get_postgres_connection(**database_credentials)
return True
def process(self, row):
# Access the values of each column in the row
shuup_id = row["shuup_id"]
user_name = row["user_name"]
customer_name = row["customer_name"]
email = row["email"]
phone = row["phone"]
marketing_permission = row["marketing_permission"]
monday_contact_id = row["monday_contact_id"]
last_login = row["last_login"]
modified_on = row["modified_on"]
values_str = "(%s,'%s','%s','%s','%s',%s,%s,'%s','%s')" %(shuup_id,user_name,customer_name,email,phone,marketing_permission,monday_contact_id,last_login,modified_on)
insert_sql = self.upsert_query %(values_str)
cur = self.conn.cursor()
try:
cur.execute(insert_sql)
self.conn.commit()
return_code = 'ok'
except Exception as err:
return_code = err
self.conn.rollback()
def close(self, error=None):
# Close connection or perform any necessary cleanup
self.conn.close()
pass
Save the DataFrame to the database table by invoking the class with foreach
callPGupdateBatch = callPGupdateClass()
### contact update -> PG - shuup_common_contact
pgstreamHandle = (contactDF.writeStream
.foreach(callPGupdateBatch)
.outputMode("Append")
.option("checkpointLocation", "~/app/spark/data/postgres/contact_change_pg/check")
.start())
pgstreamHandle.awaitTermination()
In this section, I will demonstrate how to utilize a Spark UDF to make a REST API call for syncing data to Monday.com CRM
from aws_secretmanager import *
pg_password=get_secret('pl-mac-pg')
pl_mac=get_secret('pl-mac')
fastapi_key=get_secret('pl-fastapi-key')
from pyspark.sql.functions import *
import requests
from requests.adapters import HTTPAdapter
from ast import literal_eval
import json
def callRestAPIBatch(df, batchId):
restapi_uri = "https://www.xx-aws.com/fastapi/sync_monday_contact"
@udf("string")
def callRestApiOnce(x):
session = requests.Session()
adapter = HTTPAdapter(max_retries=3)
session.mount('http://', adapter)
session.mount('https://', adapter)
payload_str=json.loads(x)
#this code sample calls an unauthenticated REST endpoint; add headers necessary for auth
headers = {'Content-Type': 'application/json', 'Authorization': 'Token %s' %(fastapi_key)}
response = session.post(restapi_uri, headers=headers, data=x, timeout=90)
if not (response.status_code==200 or response.status_code==201) :
return_code = "Response status : {} .Response message : {}".format(str(response.status_code),response.text)
else :
return_code = str(response.status_code)
# raise Exception("Response status : {} .Response message : {}".\
# format(str(response.status_code),response.text))
print("contact_update-------")
print('%s->%s|%s|%s|%s|%s' %(payload_str['request_type'],str(response.status_code),str(payload_str['shuup_id']) ,payload_str['user_name'], payload_str['marketing_permission'],convert_to_sgtime(payload_str['last_login'])))
return return_code
### Call helper method to transform df to pre-batched df with one row per REST API call ### The POST body size and formatting is dictated by the target API; this is an example
### Repartition pre-batched df for target parallelism of API calls
new_df = df.repartition(8)
### Invoke helper method to call REST API once per row in the pre-batched df
submitted_df = new_df.withColumn("api_response_code",\
callRestApiOnce(new_df["payload"]))#.collect()
submitted_df.write.format("jdbc").options(
url="jdbc:postgresql://%s:5532/shuupf" %(pl_mac),
driver="org.postgresql.Driver",
dbtable="shuup_contact_update_log",
user="kafka_id",
password=pg_password).mode("append").save()
print('Last Login ......................')
### contact update -> Monday.com
streamHandle = (contactDF.writeStream
.foreachBatch(callRestAPIBatch)
.outputMode("Append")
.option("checkpointLocation", "~/app/spark/data/postgres/contact_change/check")
.start())
streamHandle.awaitTermination()
Use schema registry to consume topic in AVRO format
I have set up a customer login topic using AVRO instead of JSON. The schema for this topic will be retrieved from the Confluent Schema Registry.
from pyspark.sql import SparkSession
spark = SparkSession\
.builder\
.appName("pyspark-streaming-PG-monday.com")\
.master("spark://192.168.1.34:7077")\
.config("spark.driver.memory","4g")\
.config("spark.driver.cores","4")\
.config("spark.cores.max","4")\
.config("spark.sql.adaptive.enabled",False)\
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
from pyspark.sql.types import *
import pyspark.sql.functions as F
from azure.keyvault.secrets import SecretClient
from azure.identity import ClientSecretCredential
import warnings
warnings.filterwarnings("ignore")
# connect to Azure Key Vault and authenticate by service principal
keyVaultName = "xxx-postgres"
KVUri = f"https://{keyVaultName}.vault.azure.net"
client_id='xxxxxxxx-xxxx-498e-87f1-xxxxxxxxxxxx'
client_secret='Ygp12~xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
tenant_id='xxxxxxxx-xxxx-xxxx-8fef-xxxxxxxxxxxx'
credential = ClientSecretCredential(client_id=client_id, client_secret=client_secret,tenant_id=tenant_id,connection_verify=False)
client = SecretClient(vault_url=KVUri, credential=credential, connection_verify=False)
# retrieve Confluent bootstrap API key and secret from Azure Key Vault
secretName = "confluent-bootstrap"
retrieved_secret = client.get_secret(secretName)
confluent_bootstrap = retrieved_secret.value
secretName = "confluent-key"
retrieved_secret = client.get_secret(secretName)
confluentApiKey = retrieved_secret.value
secretName = "confluent-secret"
retrieved_secret = client.get_secret(secretName)
confluentSecret = retrieved_secret.value
secretName = "encrypt-key"
retrieved_secret = client.get_secret(secretName
encrypt_key = retrieved_secret.value
secretName = "aks-id"
retrieved_secret = client.get_secret(secretName)
pg_password = retrieved_secret.value
secretName = "pl-mac"
retrieved_secret = client.get_secret(secretName)
pl_mac = retrieved_secret.value
secretName = "confluent-registry-schema-key"
retrieved_secret = client.get_secret(secretName)
confluent_registry_schema_key = retrieved_secret.value
secretName = "confluent-registry-schema-secret"
retrieved_secret = client.get_secret(secretName)
confluent_registry_schema_secret = retrieved_secret.value
secretName = "confluent-schema-registry-url"
retrieved_secret = client.get_secret(secretName)
confluent_registry_schema_url = retrieved_secret.value
confluentApiKey = confluent_key
confluentSecret = confluent_secret
from confluent_kafka.schema_registry import SchemaRegistryClient
def get_schema_from_schema_registry(schema_registry_url, schema_registry_subject, schema_auth):
sr = SchemaRegistryClient({'url': schema_registry_url, 'basic.auth.user.info': schema_auth})
latest_version = sr.get_latest_version(schema_registry_subject)
return sr, latest_version
# Retrieve the schema of the topic from the Confluent Schema Registry
shuup_login_topic = 'encrypt_shuup_contactuser_last_login_avro12'
schema_registry_address = "https://psrc-%s.southeastasia.azure.confluent.cloud" %(confluent_registry_schema_url)
schema_registry_url = schema_registry_address
schema_registry_subject = "%s-value" %(shuup_login_topic)
schema_auth = "%s:%s" %(confluent_registry_schema_key, confluent_registry_schema_secret)
_, login_schema = get_schema_from_schema_registry(schema_registry_url, schema_registry_subject, schema_auth)
df_contact_last_login = (spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "%s.southeastasia.azure.confluent.cloud:9092" %(confluent_bootstrap))
.option("subscribe", shuup_login_topic)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username='{}' password='{}';".format(confluentApiKey, conf
luentSecret))
.option("kafka.ssl.endpoint.identification.algorithm", "https")
.option("kafka.sasl.mechanism", "PLAIN")
.option("failOnDataLoss", "false")
.option("startingOffsets", "latest")
.option("maxOffsetsPerTrigger",1500)
.load()
.selectExpr("substring(value, 6) as avro_value")
.select(from_avro(col("avro_value"), login_schema.schema.schema_str).alias("data"))
.select(col("data.*")))
### define the customer order count table
sdf_order_count = spark.read.format("jdbc").options(
url="jdbc:postgresql://%s:5532/shuupf" %(pl_mac),
driver="org.postgresql.Driver",
dbtable="get_customer_order_count_v",
user="aks_id",
password=pg_password).load()
sdf_order_count.createOrReplaceTempView("order_count")
df_contact_last_login.createOrReplaceTempView("cust_login")
## decypt data
df_txn = spark.sql("select a.shuup_id \
, cast(aes_decrypt(username,'%s','ECB') AS STRING) as user_name \
, cast(aes_decrypt(customer_name,'%s','ECB') AS STRING) as customer_name \
, cast(aes_decrypt(email,'%s','ECB') AS STRING) as email \
, cast(aes_decrypt(phone,'%s','ECB') AS STRING) as phone \
, marketing_permission, monday_item_id as monday_contact_id, a.last_login, a.modified_on from cust_login a" %(encrypt_key, encrypt_key, encrypt_key, encrypt_key))
df_txn.createOrReplaceTempView("cust_login_order")
### This process involves data enrichment to determine the total order count for each customer within the last 30 days.
lcontactDF = spark.sql("select a.*, b.order_count from cust_login_order a , order_count b where a.shuup_id = b.customer_id")
lcontactDF = lcontactDF.withColumn("payload", to_json(struct(col("*"))))
lcontactDF = lcontactDF.drop("order_count")