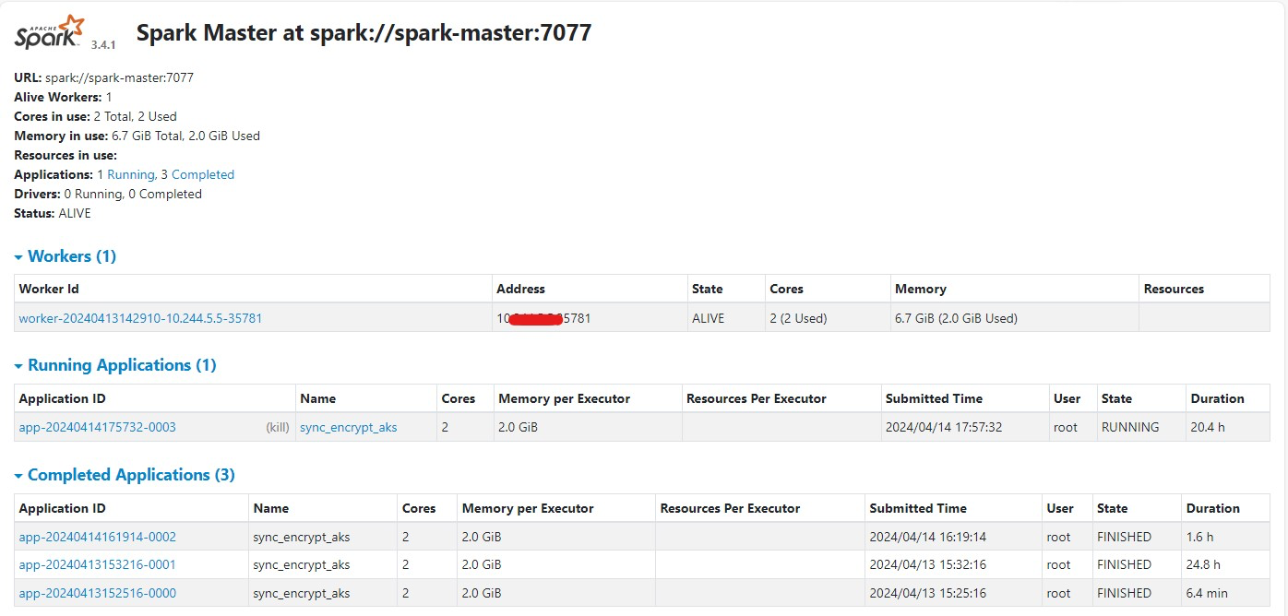
Deploying Spark on Kubernetes
Let's build a custom Docker image for Spark 3.4.1, designed for Spark Standalone Mode
Dockerfile. I found scripts in the spark-kubernetes repo on GitHub and change the Spark and hadoop version.
# base image
FROM openjdk:11
# define spark and hadoop versions
ENV SPARK_VERSION=3.4.1
ENV HADOOP_VERSION=3.3.6
# download and install hadoop
RUN mkdir -p /opt && \
cd /opt && \
curl https://archive.apache.org/dist/hadoop/common/hadoop-${HADOOP_VERSION}/hadoop-${HADOOP_VERSION}.tar.gz | \
tar -zx hadoop-${HADOOP_VERSION}/lib/native && \
ln -s hadoop-${HADOOP_VERSION} hadoop && \
echo Hadoop ${HADOOP_VERSION} native libraries installed in /opt/hadoop/lib/native
# download and install spark
RUN mkdir -p /opt && \
cd /opt && \
curl https://archive.apache.org/dist/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop3.tgz | \
tar -zx && \
ln -s spark-${SPARK_VERSION}-bin-hadoop3 spark && \
echo Spark ${SPARK_VERSION} installed in /opt
# add scripts and update spark default config
ADD common.sh spark-master spark-worker /
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
Docker file for Spark UI I used this repo on GitHub
FROM python:2.7-alpine
COPY ./spark-ui-proxy.py /
ENV SERVER_PORT=80
ENV BIND_ADDR="0.0.0.0"
EXPOSE 80
ENTRYPOINT ["python", "/spark-ui-proxy.py"]
Build the Spark image and upload to docker
docker build -t spark-standalone-cluster:3.4.1 .
List the image
docker image ls spark-standalone-cluster:3.4.1

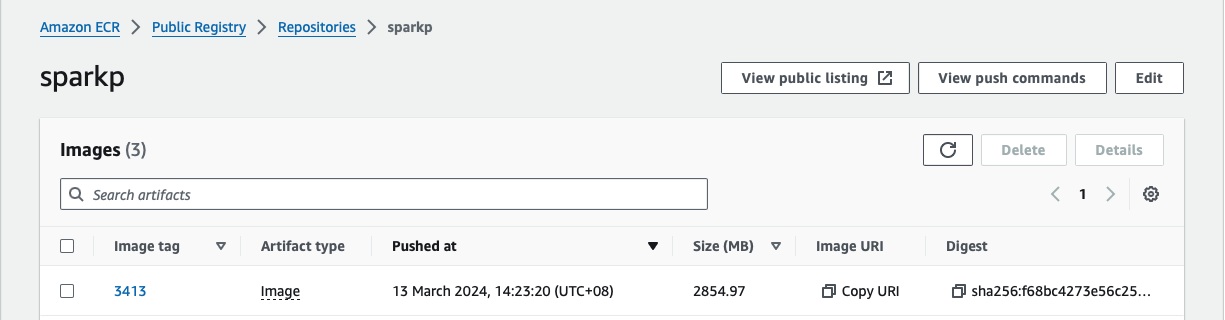
Upload the docker image to ECR
docker tag spark-standalone-cluster:3.4.1 public.ecr.aws/n4rxxxxx/sparkp:341
docker push public.ecr.aws/n4rxxxxx/sparkp:341
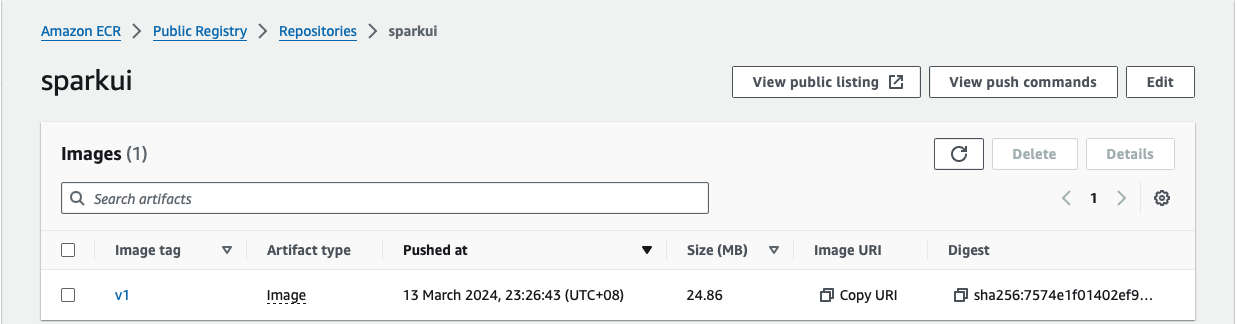
Build the Spark ui image and upload to ECR
docker build -t sparkui .
docker tag spark-ui:1.0.1 public.ecr.aws/n4rxxxxx/sparkui:v1
docker push public.ecr.aws/n4rxxxxx/sparkui:v1
With the docker images for images in ECR , we can deploy the Spark Master , Worker and UI in EKS
Spark Master
kind: ReplicationController
apiVersion: v1
metadata:
name: spark-master-controller
namespace: spark
spec:
replicas: 1
selector:
component: spark-master
template:
metadata:
labels:
component: spark-master
spec:
hostname: spark-master-hostname
subdomain: spark-master-headless
containers:
- name: spark-master
image: public.ecr.aws/n4rxxxxx/sparkp:3413
imagePullPolicy: Always
command: ["/spark-master"]
ports:
- containerPort: 7077
- containerPort: 8080
resources:
requests:
cpu: 1000m
memory: 2Gi
volumeMounts:
- mountPath: "/mnt/crm"
name: volume
readOnly: false
volumes:
- name: volume
persistentVolumeClaim:
claimName: crm-poc-pvc
kind: Service
apiVersion: v1
metadata:
name: spark-master-headless
namespace: spark
spec:
ports:
clusterIP: None
selector:
component: spark-master
---
kind: Service
apiVersion: v1
metadata:
name: spark-master
namespace: spark
spec:
ports:
- port: 7077
targetPort: 7077
name: spark
- port: 8080
targetPort: 8080
name: http
selector:
component: spark-master
Create PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: crm-poc-pvc
namespace: spark
spec:
accessModes:
- ReadWriteMany
storageClassName: azurefile-csi-premium
resources:
requests: storage: 5Gi(base)
Spark Worker
kind: ReplicationController
apiVersion: v1
metadata:
name: spark-worker-controller
namespace: spark
spec:
replicas: 1
selector:
component: spark-worker
template:
metadata:
labels:
component: spark-worker
spec:
containers:
- name: spark-worker
image: public.ecr.aws/n4rxxxxx/sparkp:3413
imagePullPolicy: Always
command: ["/spark-worker"]
ports:
- containerPort: 8081
resources:
requests:
cpu: 2000m
memory: 2Gi
volumeMounts:
- mountPath: "/mnt/crm"
name: volume
readOnly: false
volumes:
- name: volume
persistentVolumeClaim:
claimName: crm-poc-pvc
Spark UI
kind: ReplicationController
apiVersion: v1
metadata:
name: spark-ui-proxy-controller
namespace: spark
spec:
replicas: 1
selector:
component: spark-ui-proxy
template:
metadata:
labels:
component: spark-ui-proxy
spec:
containers:
- name: spark-ui-proxy
image: public.ecr.aws/n4rxxxxx/sparkui:v1
ports:
- containerPort: 80
resources:
requests:
cpu: 100m
args:
- spark-master:8080
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 120
timeoutSeconds: 5
kind: Service
apiVersion: v1
metadata:
name: spark-ui-proxy
namespace: spark
spec:
ports:
- port: 80
targetPort: 80
selector:
component: spark-ui-proxy
type: LoadBalancer
To trigger the spark job automatically , we create cronjob to enable it to retrieve the source codes from PVC. Before setup the cronjob , it's required to create the role, role binding and service account to grant the access to let the cronjob pod to access the Spark pod in EKS
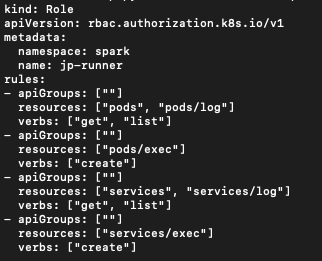
Role
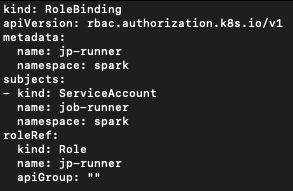
RoleBinding
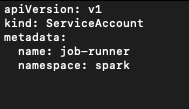
Service Account
Cronjob
apiVersion: batch/v1
kind: CronJob
metadata:
name: spark-encrypt-cron-job
namespace: spark
spec:
schedule: "*/1 * * * *" # Runs every minute
jobTemplate:
spec:
template:
spec:
serviceAccountName: job-runner
containers:
- name: cron-job-container
image: bitnami/kubectl:latest
command:
- /bin/sh
- -c
- kubectl -n spark exec -it svc/spark-master -- sh /mnt/crm/aks_test/check_shuup_aks_encrypt.sh
#command: ["echo", "Hello from the CronJob! This is a sample command."]
volumeMounts:
- mountPath: "/mnt/crm"
name: volume
readOnly: false
volumes:
- name: volume
persistentVolumeClaim:
claimName: crm-poc-pvc
restartPolicy: OnFailure
Shell script call by cronjob. It check if the spark job is running , only trigger another shell script to run Spark streaming job if it's not running
ps -ef|grep pyspark_test_aks_confluent_encrypt|grep -v grep
STATUS=$?
current_time=$(date +"%Y-%m-%d %H:%M:%S")
echo "Current date and time: $current_time"
if [ $STATUS -ne 0 ] ; then
echo $current_time ' spark aks job is not running-- > ' > /mnt/crm/aks_test/log/spark_aks_not_running.log
sh /mnt/crm/aks_test/shuup_aks_confluent_encrypt.sh
else
echo $current_time ' spark aks job is running-- > ' > /mnt/crm/aks_test/log/spark_aks_running.log
fi
Shell script for Spark streaming. It's triggered by spark-submit
spark-submit --name "sync_encrypt_aks" --master spark://spark-master:7077 \
--py-files "/mnt/crm/aks_test/db_connect.py,/mnt/crm/aks_test/shuup_pg.py" \
--executor-memory 2G \
--total-executor-cores 2 \
--packages org.postgresql:postgresql:42.2.14,org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.1 \
/mnt/crm/aks_test/pyspark_test_aks_confluent_encrypt.py > /mnt/crm/aks_test/tmpoutfile1 2>&1

service created for Spark Master and UI

pod created for Spark Master , Worker and UI