Real-Time Data Streaming with Kafka and Spark
In my latest project, I am driven by the requirements of a new omnichannel initiative aimed at enhancing CRM lead processing for near real-time efficiency. This project focuses on leveraging cutting-edge technologies like Kafka and Spark for real-time data streaming, synchronizing lead data from a PostgreSQL database to Microsoft Dynamics 365. By utilizing Spark UDFs and advanced multitasking capabilities, my goal is to optimize the data synchronization process and enable seamless integration across systems.
As I embarked on this journey, it was vital to validate the solution's efficiency and reliability through a successful POC within my personal network. This POC serves as proof of my proficiency in designing data-intensive projects and developing robust solutions tailored to specific business requirements and technological aspirations.
Let's uncover the specifics of this POC together as we track the flow of data and explore the technical foundations. I have smoothly integrated Monday.com for CRM, utilized AWS EKS for hosting, and employed the Confluent Platform for data streaming in this trial. While Monday.com enhances lead management efficiency, AWS EKS manages the database, Spark, and other components, with the Confluent Platform overseeing data streaming. This streamlined setup ensures reliability and scalability to meet the demands of processing real-time data in the Omnichannel project.
In this design, we aim to seamlessly integrate these powerful tools into a smooth architecture that enables the continuous flow of data from source to destination, ensuring timely and accurate information delivery. By leveraging the scalability of Confluent Cloud, the processing capabilities of Apache Spark, the connectivity of Kafka Connect, the data persistence of Postgresql, and the CRM functionalities of Microsoft Dynamics 365, we can create a comprehensive solution that meets the real-time data streaming requirements of today's dynamic business environments.
For a visual representation of the CRM real-time lead capturing system's architecture, an architecture diagram has been created and shared below. This visualization offers a comprehensive view of how these components work together to process and synchronize data efficiently, demonstrating the system's scalability and reliability. By utilizing AWS EKS for hosting and integrating key services like Confluent Platform, the design ensures seamless real-time data processing to meet the omnichannel initiative's requirements.

Producers/Consumers
In the Kafka platform, we utilize the producer/consumer paradigm for data processing.
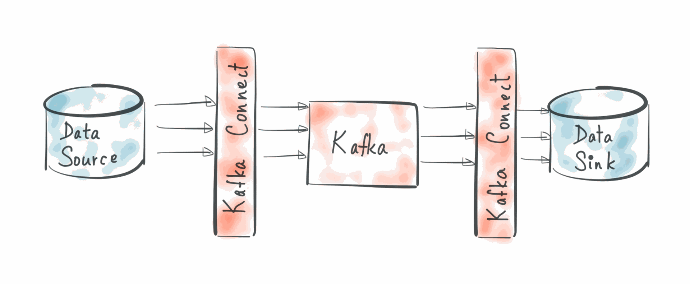
For producers, our approach involves using the Kafka Connect JDBC Source Connector. This connector is user-friendly, and stable, requiring minimal implementation effort through configuration settings. Key steps include setting up the connector to establish a connection with the JDBC data source, defining source configurations like database URL, credentials, tables to stream, filters, and transformations, and configuring data publication to specific Kafka topics in Confluent Cloud.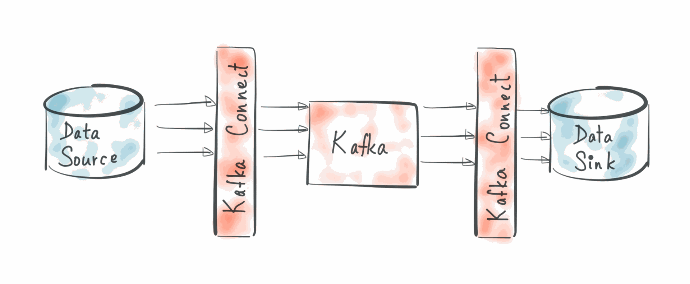
Click here to see how to configure JDBC Source Connectors for Customer Login and Website activity in the POC. The Kafka Connector configuration includes settings to retrieve credentials from Azure Key Vault
On the consumer side, we employ Apache Spark Structured Streaming to consume data from Kafka topics and synchronize it with either Postgresql database tables or CRM entities.
With Spark Structured Streaming, we build an application that ingests data from Kafka topics, enriches it by joining with Postgresql tables, defines the data schema, and persists it in the Postgres database. Spark utilizes User-Defined Functions (UDFs) to concurrently call web APIs through its multitasking capability for synchronizing data with Monday.com. This approach ensures efficient data processing and seamless integration with Monday.com, meeting the authentication and format requirements of the CRM.

Click here to see how Spark consume Kafka Topic and call Postgresql function or stored procedure for Database update
Fault Tolerance
In Spark Structured Streaming, the framework manages Kafka topic offsets internally and does not commit offsets in Kafka itself. This behavior ensures fault tolerance and guarantees that processing resumes from the last committed offset in case of failures. Spark Structured Streaming supports Exactly-Once semantics through a control process table that enables idempotency and ensures data consistency during processing.
For more in-depth information on how Spark Structured Streaming supports Exactly-Once semantics and its fault tolerance mechanisms, you can refer to this link for the official document of Spark Structured Streaming
By incorporating these fault tolerance measures, the system can efficiently handle failures and ensure data consistency, enhancing the overall reliability and resilience of the real-time data processing workflow.
After detailing the fault tolerance mechanisms, a data flow diagram has been included to illustrate how data flows through the pipeline. This visual representation showcases the interaction between Kafka, Spark Structured Streaming, PostgreSQL, CRM Monday.com, and other components

Monitoring
Establish monitoring and logging systems to track data streaming progress and detect errors. Utilize Elasticsearch with JMX for enhanced monitoring capabilities. Set up alerts and notifications for critical events to maintain system reliability and performance.
Challenges and Solutions
Challenges Faced:
- Real-time Data Streaming Processing: The data streaming pipeline operates continuously, enabling seamless and uninterrupted flow of information. Implementing near real-time data processing has been a significant challenge, requiring quick and reliable synchronization between systems to ensure timely and efficient data handling.
- Integrating Multiple Technologies: A significant challenge we encountered was coordinating the integration of Confluent Cloud and Microsoft Dynamics 365. This required careful planning to ensure smooth interoperability, particularly considering Dynamics 365's unique database structure. Unlike traditional databases, Dynamics 365 does not support SQL queries for data synchronization, thus requiring the use of REST APIs for data updates. This distinctive requirement added complexity to the data integration process, underscoring the necessity for specialized approaches when syncing data with Dynamics 365.
- Optimizing Performance: Ensuring optimal performance while handling large volumes of lead data and maintaining data integrity throughout the sync process was a critical challenge.
- Ensuring Data Privacy and Security: With Confluent Cloud operating outside our company network, safeguarding sensitive company data within Confluent Cloud becomes paramount. To protect any Personally Identifiable Information (PII) and maintain data privacy, encryption is crucial across multiple levels.
Approach to Solving Challenges:
- Architecture Design: I designed a robust architecture to ensure seamless data flow, incorporating high availability and fault tolerance measures. By deploying producers and consumers within Kubernetes clusters, we enhance the reliability and resilience of the system. Confluent Cloud serves as the messaging bus, while Spark Structured Streaming handles real-time processing efficiently. This setup not only guarantees continuous data streaming but also provides the necessary redundancy and fault tolerance required for uninterrupted operation in the data pipelines.
- Utilizing Spark UDFs: Leveraging Spark UDFs, I implemented custom data transformation functions to ensure accurate mapping of lead data between PostgreSQL and Dynamics 365.
- Performance Optimization: Performance Optimization: Employing rigorous performance testing and leveraging the capabilities of Spark UDFs and multitasking, I optimized the solution to fulfill near real-time processing demands while ensuring consistent data accuracy. This approach involved fine-tuning the system to enhance efficiency and maintain optimal performance levels throughout the data processing pipeline.
- Implementing Data Encryption:
- Data Encryption at Rest for Confluent Cloud Cluster: Implement robust encryption methods to secure data while at rest within the Confluent Cloud Cluster. Utilize encryption techniques such as Transparent Data Encryption (TDE) to safeguard data stored in Confluent Cloud databases.
- Encryption During Data Transmission: Ensure encryption protocols are in place to secure data during transmission. Use SSL/TLS protocols for secure communication between systems, preventing unauthorized access to sensitive information during data transfer.
- Pre-Transmission Data Encryption: Encrypt data before transmitting it to Confluent Cloud to prevent unauthorized access. Utilize AES256 encryption algorithms to protect sensitive data from potential breaches, ensuring data privacy and integrity are maintained throughout the transmission process.
I have included a series of technical posts sharing valuable insights, sample codes, and configurations that can be reused in the omnichannel project. These resources encompass a wide range of topics, such as sample codes for Spark Structured Streaming programming both for pyspark and scala, deploying Scala applications using SBT, Terraform scripts for Kafka cluster automation, deploying Kafka Connect to Kubernetes and setting up Spark on Kubernetes.
By integrating these resources into the design document, developers will benefit from a repository of ready-to-use configurations and sample codes, eliminating the need to start from scratch. This comprehensive collection aims to expedite the development process and facilitate seamless implementation of various technical components within the omnichannel project.
Sync Table via Kafka Connect
Synchronizing a table to another database using Kafka JDBC Connectors is a simple process requiring just configuration, concluding within minutes
Sync Topic via Spark Scala
With Spark's multi-tasking capabilities, the process of consuming a Kafka topic and synchronizing it with a traditional database table can be incredibly fast, surpassing your expectations

Deploy Scala application via SBT

Create Confluent Cloud Cluster via Terraform
Let's deep dive to the first step to create a Kafka cluster in Confluent Cloud with the Confluent Terraform Provider
Deploy Kafka Connect to EKS
By running Kafka Connect on-premise, we can ensure data residency compliance, maintain security protocols specific to out environment, and have more direct management over resource allocation and monitoring

Spark Structured Streaming
With Spark structured streaming, we can consume the Kafka topic and join it with other traditional database tables to enrich the data before synchronizing it with other systems.
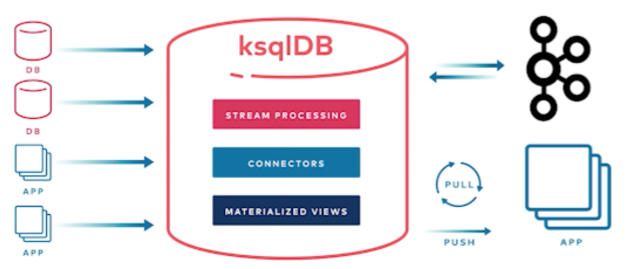
ksqlDB & Kafka Streams
In order to create a stream on top of the topic , we need to create a ksqlDB cluster
Spark on Kubernetes
Spark's distributed computing capabilities make it ideal for processing large-scale data and running complex analytics workloads. By deploying Spark on Kubernetes, users can benefit from the scalability and resource efficiency of Kubernetes, which automates the management of containerized applications. This combination enables seamless resource utilization, dynamic scaling, and isolation for Spark workloads, making it easier to manage and operate Spark clusters in a containerized environment.
