Sync Topic via Spark
I have previously covered data synchronization via Kafka Connect in an earlier post. In this post, I will illustrate how to synchronize a Kafka topic to another database table using the same data source as previously discussed. Spark took 27 seconds, while the Kafka JDBC sink connector took 34 seconds.
I used spark-shell to run the scala scripts to consume kafka topic and save in postgres db table
spark-shell \
--master spark://192.168.1.34:7077 \
--total-executor-cores 16 \
--driver-memory 2g \
--executor-memory 4g \
--packages io.confluent:kafka-schema-serializer:7.4.0,org.apache.spark:spark-avro_2.12:3.4.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.1
spark-shell \
--master spark://192.168.1.34:7077 \
--total-executor-cores 16 \
--driver-memory 2g \
--executor-memory 4g \
--packages io.confluent:kafka-schema-serializer:7.4.0,org.apache.spark:spark-avro_2.12:3.4.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.1
import org.apache.spark.sql.avro.functions._
import org.apache.avro.SchemaBuilder
import org.apache.avro.Schema
import org.apache.spark.sql.avro.SchemaConverters
import org.apache.spark.sql.types._
import io.confluent.kafka.serializers.KafkaAvroDeserializer
import io.confluent.kafka.schemaregistry.client.rest.RestService
// to consume kafka topic from beginning
val df_txn = (spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "xxxxxxxxxx.xxxxxcloud.com:9092")
.option("subscribe", "pg_shuup_txn_avro_02")
.option("startingOffsets", "earliest")
.load())
spark.sparkContext.setLogLevel("Error")
val brokerServers = "xxxxxxxxx.xxxxxcloud.com:9092"
val topicName = "pg_shuup_txn_avro_02"
val schemaRegistryURL = "http://xxxxxxxxx.xxxxxcloud.com:8081"
val restService = new RestService(schemaRegistryURL)
val exParser = new Schema.Parser
//-- to retrieve the schema for value only
val schemaNames = Seq("value")
val schemaStrings = schemaNames.map(i => (i -> restService.getLatestVersion(s"$topicName-$i").getSchema)).toMap
val tempStructMap = schemaStrings.transform((k,v) => SchemaConverters.toSqlType(exParser.parse(v)).dataType)
val schemaStruct = new StructType().add("key", tempStructMap("key")).add("value", tempStructMap("value"))
//-- For value only
val schemaStrings = restService.getLatestVersion(s"$topicName-value").getSchema
// The magic goes here: // Skip the first 5 bytes (reserved by schema registry encoding protocol)
val df_avro = df_txn.select(from_avro(expr("substring(value, 6)"),schemaStrings).as("value"))
val df_txn = df_avro.select("value.*").repartition(16)
// to be continued
import org.apache.spark.sql.{DataFrame, SaveMode}
// to save the streaming dataframe to postgres db table
def saveToPostgres(df: DataFrame, jdbcUrl: String, tableName: String, user: String, password: String): Unit = {
df.write
.format("jdbc")
.option("url", jdbcUrl)
.option("dbtable", tableName)
.option("user", user)
.option("password", password)
.mode(SaveMode.Append)
.save()
}
val tableName = "shuup_txn_avro"
val jdbcUrl="jdbc:postgresql://xxxxxxxxx.xxxxxcloud.com:5532/shuupf"
val user ="spark_id"
val password = "!forgot430"
val query = df_txn.writeStream
.outputMode("append")
.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
saveToPostgres(batchDF, jdbcUrl, tableName, user, password)
}
.option("checkpointLocation", "~/app/spark/data/postgres/scala/shuup_txn_test/check")
.start()
.awaitTermination()
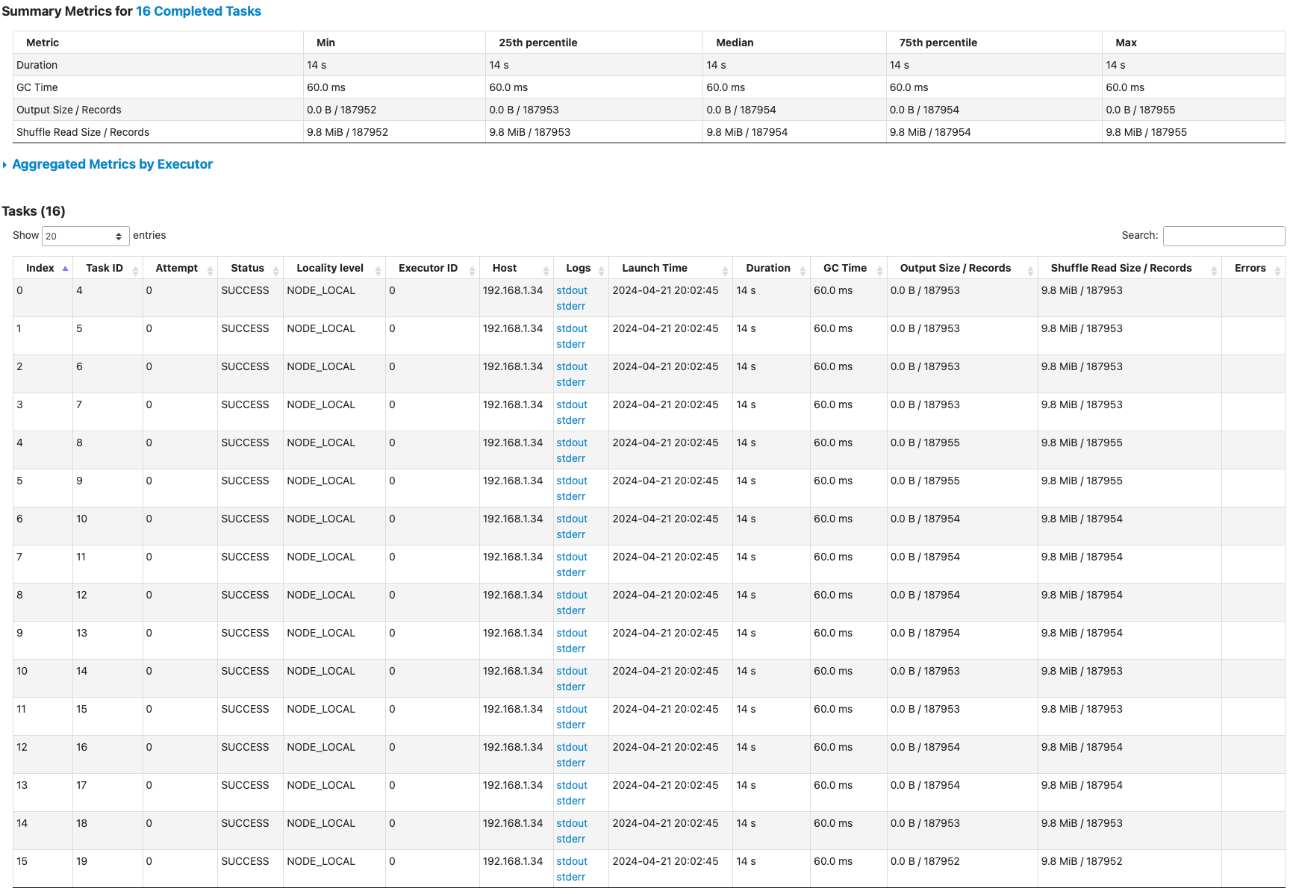
In the Spark UI, we can observe that it took 27 seconds to consume the Kafka topic and save the data in the PostgreSQL database table.

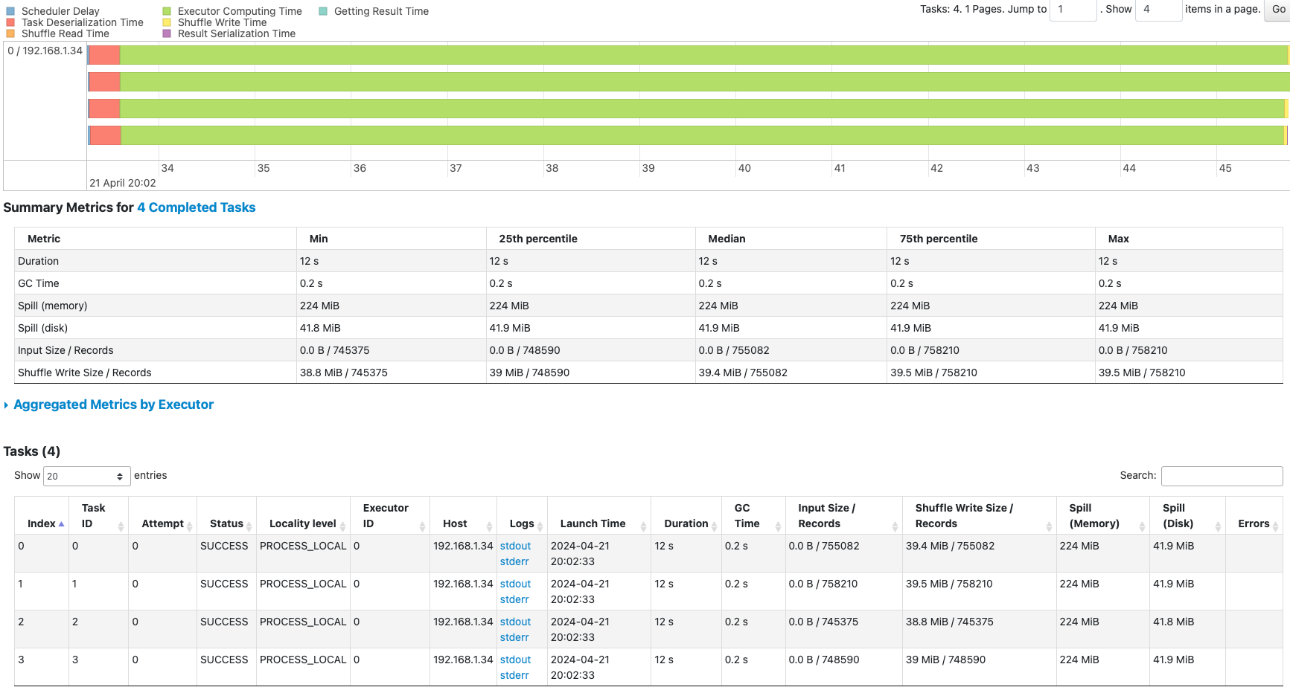
With 4 partitions in the topic, Spark handles 4 tasks to consume the data concurrently. Subsequently, the data is synchronized to the PostgreSQL database table using 16 tasks

It took 13 seconds to consume the Kafka topic with 4 tasks
It took 14 seconds to save the data in postgres database table with 16 tasks